はじめに
Node.jsで日本語をカタカナ・ひらがな・ローマ字に変換したい場合、まずKuroshiroというライブラリに行き当たります。
このKuroshiroを使ってみたのでメモとして残しておきます。
公式サイト:
https://kuroshiro.org
npm
https://www.npmjs.com/package/kuroshiro
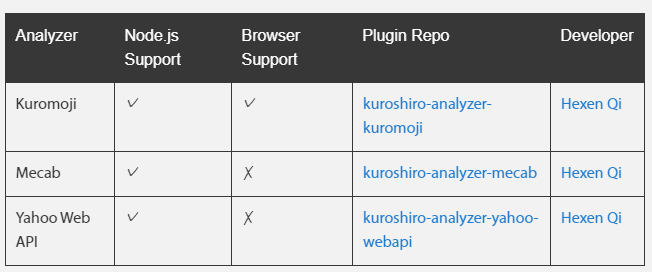
アナライザーとしては「Kuromoji」「Mecab」「Yahoo」が用意されています。
しかし、Mecabはメモリー使用率が高く重い。Yahooは動作しませんでした。長い間メンテナンスされていないので仕方ないところはあります。まぁYahooはWebAPIを直接利用すればよいと思います。
そのため、Kuromoji のみですが使い方を残しておきます。
使い方
インストール
npm install kuroshiro
npm install kuroshiro-analyzer-kuromojiコード
使用する場合のコードは次のようになります。
公式のマニュアルとは違いasync-awaitを使用しています。
const Kuroshiro = require("kuroshiro")
const kuroshiro_kuromoji = new Kuroshiro();
const KuromojiAnalyzer = require("kuroshiro-analyzer-kuromoji");
kuroshiro_kuromoji.init(new KuromojiAnalyzer());
async function kanji2yomi_kuroshiro(text) {
result = await kuroshiro_kuromoji.convert(text, { to: "hiragana" });
//console.log(result)
return (result)
}Expressの場合は次のように使えばいいです。
router.get('/kanji2yomi_kuroshiro', async function (req, res, next) {
res.send(await kanji2yomi_kuroshiro(req.query.text))
});品質について
少し試した限り、あまりKuromojiの品質は高くありませんでした。
固有名詞に弱く、「筑波山」を「つくばやま」にしたりします。
このあたりは、Yahooの方が品質は高いと思います。
Yahooより品質を求める場合はMecab方式で固有名詞の辞書を用意した方がいいでしょう。
ただ、最低限の変換はやってくれるので品質を求めなければ気軽に使用できてよいと思います。
コメント