OpenObserveとは?
ログの集約・管理サーバーです。
splunkやdatadogを置き換えることを目指しており、なんとストレージコストを1/140にできることを売りにしています。

環境
OS: Rocky Linux 8.6
OpenObserve: 0.5.2
インストール
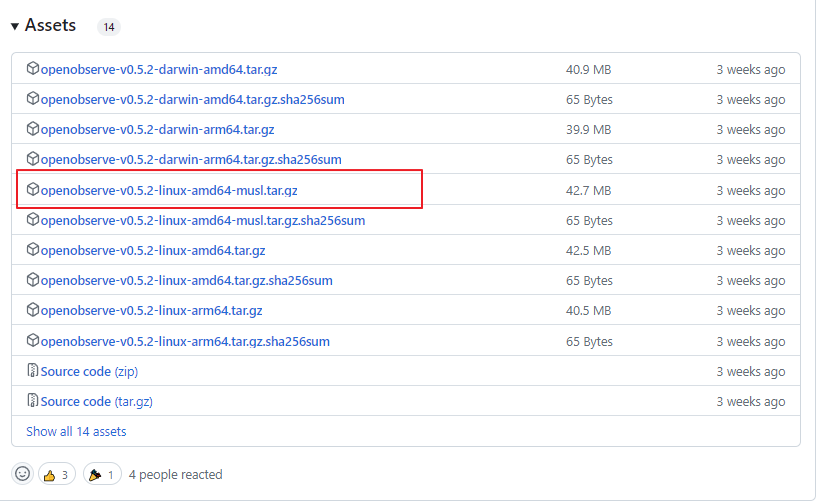
github の release から最新のバージョンのリンクを取得。
muslを使用するのが簡単ですが、パフォーマンスが落ちるようです。
本番環境の場合はmuslでないバージョンを使用した方がいいかもしれません。
リンクを取得したら、wget & 解凍 & 実行。
初回起動時にZO_ROOT_USER_EMAIL / ZO_ROOT_USER_PASSWORD を変更してアカウントを設定する必要があります。適当に設定しておきましょう。
# wget https://github.com/openobserve/openobserve/releases/download/v0.5.2/openobserve-v0.5.2-linux-amd64-musl.tar.gz
# tar -zxvf openobserve-v0.5.2-linux-amd64-musl.tar.gz
# ZO_ROOT_USER_EMAIL="root@example.com" ZO_ROOT_USER_PASSWORD="Complexpass#123" ./openobserveサーバーに接続します。ポートは5080です。
Firewallがある場合はポートを空けましょう。
http://192.168.0.100:5080常駐させる場合はsystemdを設定します。

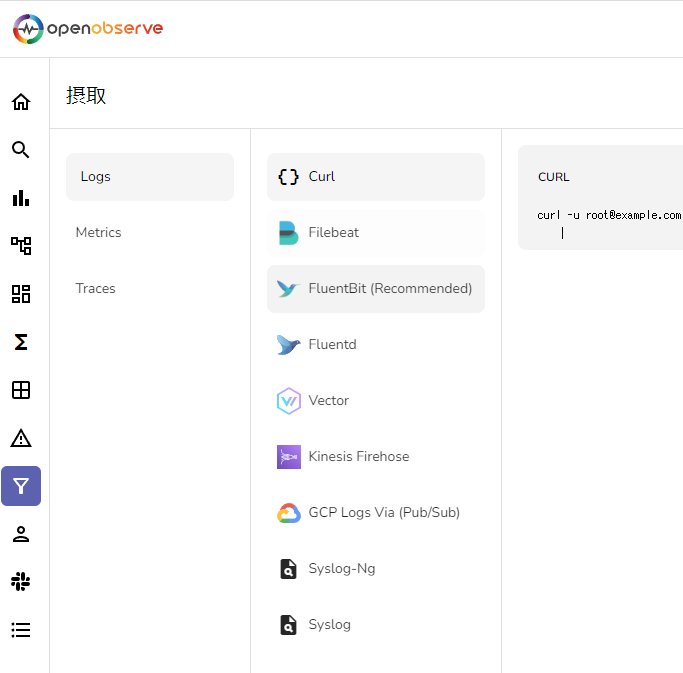
入力
「摂取」というメニューがあるので、そこからログの受け取りを設定します。(日本語化がイマイチ)
使用例が表示されるので設定方法は分かりやすいと思います。
良いところ
・GUIのデザインが洗練されている
・ストレージを消費しないとの謳い文句通り、ログで消費するストレージ容量は実際に少ない。tar.zpに比べたらサイズは大きいが、ElasticSearchよりはかなりマシ
・軽量でサーバー負荷が小さい (Elasticsearchが激重すぎるのかも)
悪いところ
・Dashboardが作りにくい
COUNTどこ?
・Extractorが無い
調べた限り、extractorが無いです。
JSONが多段になっている場合、検索時にフィルターとしたり、ダッシュボードでフィールドとして設定できません。
おそらくFunctionでSQLを使用して設定するのだと思いますが、分かりにくいことこの上ないです。私は詰みました。
・(恐らく)検索は遅い
インデックスを使用せず、全文検索システムを導入しないことで軽量にしているため、ログ量が増えると検索は遅くなると思います(要検証)
・GeoIPは使えない
・アラートにメールが無い
基本的にHTTP GET/POSTなどを使用する方式のみ。slackやdiscordのWebhookは使用できる。
評価
総合評価として、特にExtractorが無いのは厳しいと感じます。
ログのフォーマットは多種多様なもののため、システムに合わせて変えられないのは面倒です。
かなり入力形式を選びます。
ただ、検索をほとんど使わないような環境ではElasticsearchを使用したシステムよりも軽量でコストも低くなるため、候補になりやすいと思います。
生のデータベースでしかないため、Grafanaとの連携なども容易です。
将来性は非常に感じますが、今のところは既存システムを置き換えるほどではないという印象でした。
今のところは、graylogなどを使用した方がいいかもしれない。
参考


コメント